
Apusic应用服务器对集群服务提供了优异的支持,通过Apusic集群服务,企业应用能够获得高可用性及水平可扩展性.
Apusic集群主要包括Web集群、JNDI集群、EJB集群、JMS集群。
一般来说,Web集群试图解决两个问题:客户请求的负载均衡和Session的高可用性。
Apusic Web集群为这两个问题提供了灵活、全面的解决方案。客户请求的负载均衡是指客户的请求依赖特定算法被合理地分配给多台Web Server来处理。Session的高可用性是指当某台Web Server失效,这台Web Server服务的客户的请求会被透明地转发给其它有效Web Server,而会话状态(Session)依然可用。我们把集群范围内具有高可用性的Session称为集群Session。
Apusic Session集群采取Instant Replication,即某节点的Session操作是即时传播(同步)到集群中的其它节点的;一些应用服务器厂商的集群Session同步采取非即时的方式,这会降低Session可用性。还有一个比较常见的场景是新节点加入工作中的Apusic集群时,新节点的Session会自动与集群同步。
接下来我们来看一下,使用Apusic LoadBalance和第三方LoadBalance作为负载均衡器时,分别如何实现客户请求的负载均衡和Session的高可用。
Apusic在web层实现了负载均衡。利用Apusic建立的负载均衡集群有一个很重要的特点就是Apusic实现了分布式Session管理,这也是实现Web服务器集群的关键,由于Web应用被分布到多台服务器上运行,因此保存在Session中的共享数据必须完全保持一致。Apusic没有使用共享数据库来保存Session数据,虽然这种方式能保证Session数据的一致性,但由于Session的变化是很频繁的,对数据库将造成很大的压力,最终将成为整个系统的瓶颈,Apusic使用一种分布式Session服务,每个服务器管理自己所产生的Session。当Web应用从一台服务器迁移到另一台服务器时,Session也会自动进行迁移,这样使得对Session的管理被均匀地分布到所有的服务器上,任何一台服务器失效并不会使Session丢失。对应用开发者来说,要保证分布式Session能够正常工作,在Session中只能保存实现了java.io.Serializable的数据,否则Session将无法完成迁移。
采用Apusic作为负载均衡器时, Apusic提供三种负载均衡策略:
随机选择策略 随机选择其中一台服务器处理请求。
Round-Robin策略 依次轮寻选择一台服务器处理请求。
权重策略 按照权重的比例选择服务器处理请求。
当然,用户也可以手动扩展自己的负载均衡策略,如何扩展负载均衡策略,请参考配置负载均衡。
Apusic LoadBalancer使用了内存复制技术,将每个后置服务器的Session备份在自己的缓存中,即后台某个节点处理完客户端请求时,将当前Session复制到负载均衡器中。所以使用Apusic LoadBalance时,集群中每个节点必须开启SessionService中的复制服务(如何开启复制服务请参考配置负载均衡)。
采用Apusic LoadBalance时,由于Session缓存在Apusic LoadBalance的缓存中,当主节点失效时,Apusic LoadBalance从缓存取出当前的Session,将Session带到下一个节点进行处理,确保Session的可用性。如下图:

Apusic负载均衡器是用Apusic应用服务器实现的,也就是说,负载均衡器和其他Apusic应用服务器没有多少区别,不同的是它上面没有安装应用系统,并且使用不同的配置文件,它只是专门提供负载均衡服务。客户通过访问负载均衡器的Web服务,来访问整个集群的资源。用户请求到达负载均衡器后,负载均衡器将它分配到某个Apusic应用服务器上,让这个应用服务器为此用户提供服务。
负载均衡器配置文件为$DOMAIN_HOME/config/loadbalancer.conf,缺省内容见附录,下面是其中LoadBalancer服务的片段:
<SERVICE
CLASS="com.apusic.web.loadbalancer.LoadBalancer"
>
<ATTRIBUTE NAME="ServerPort" VALUE="80"/>
<ATTRIBUTE NAME="BackendServers" VALUE="192.168.6.66:6888,192.168.6.67:6888"/>
<ATTRIBUTE NAME="MaxWaitingClients" VALUE="500"/>
<ATTRIBUTE NAME="WaitingClientTimeout" VALUE="5"/>
<ATTRIBUTE NAME="KeepAlive" VALUE="True"/>
<ATTRIBUTE NAME="MaxKeepAliveRequests" VALUE="100"/>
<ATTRIBUTE NAME="KeepAliveTimeout" VALUE="15"/>
<ATTRIBUTE NAME="MaxKeepAliveConnections" VALUE="300"/>
<ATTRIBUTE NAME="EnableLog" VALUE="False"/>
<ATTRIBUTE NAME="LogFileName" VALUE="logs/access.log"/>
<ATTRIBUTE NAME="LogFileLimit" VALUE="1000000"/>
<ATTRIBUTE NAME="LogFileCount" VALUE="10"/>
</SERVICE>
与Apusic应用服务器的配置文件config/apusic.conf比较一下,可以发现少了一些服务描述,但多了一个LoadBalancer服务。
当用这个配置文件启动Apusic应用服务器时,这台服务器就成为一个负载均衡器。
在配置文件中,最关键的属性BackendServers,定义了集群中的服务器,这是一个用逗号分割的地址列表,包括主机名和端口号。
Apusic负载均衡器默认情况下是会话粘滞(session-stick)的,同时采用轮循的策略选择可用节点。当然你也可以关闭会话粘滞,只要在LoadBalancer服务中,增加属性:
<ATTRIBUTE NAME="SessionStick" VALUE="false"/>
就可以关闭会话粘滞。如果想采用其他策略来选择节点,可以增加属性:
<ATTRIBUTE NAME="BalancePolicy" VALUE="Random"/>
其中Value值可以选择:Random,Round-Robin,LoadWeight.注意当用户选择LoadWeight的时候,还需要增加属性:
<ATTRIBUTE NAME="LoadWeight" VALUE="10,20,70"/>
来标识权重的值。其值与服务器地址列表中的服务器一一对应。此外,用户还可以扩展自己的负载均衡策略,只要实现LoadBalancePolicy接口,同时增加属性:
<ATTRIBUTE NAME="BalancePolicyClass" VALUE="userclass "/>
其中Value值为用户自定义的类。当两个属性BalancePolicy,BalancePolicyClass同时存在时,BalancePolicyClass的优先级高。
注意:要使用Session的分布式功能,集群中每台Apusic服务器的SessionService中属性: <ATTRIBUTE NAME="Distributable" VALUE="True"/>值必须为True。默认情况下为False。
当上面的配置完成后,负载均衡器可以通过命令行方式启动,不同的是需要增加-config参数指明负载均衡器的配置文件,例如:java -classpath E:\apusic\lib\apusic.jar; E:\apusic\lib\javac.jar;E:\apusic\lib\mejb.jar;E:\apusic\common\javaee.jar; com.apusic.server.Main -root E:\apusic\domains\mydomain -config /config/loadbalancer.conf
Apusic Http Server是在Apache Http Server基础上对其负载均衡功能进行了优化而产生的Apusic Web服务器,其与Apusic应用服务器有更好的耦合性。详细请参考:第 60 章 使用Apusic Http Server作为负载均衡前置机
Apusic集群对第三方的负载均衡(如:硬件负载均衡器F5, 软件负载均衡器 Apache Server,微软的IIS等)提供良好的支持,用户只需要简单配置就可以使第三方的负载均衡器与Apusic完美结合在一起。
当采用第三方负载均衡器时,Apusic同样采用内存复制技术,与Apusic LoadBalancer不同的是,我们已经不能用第三方负载均衡器来备份状态,下面介绍两种其他方法。
第一种方式,使用IP多播技术:
在Apusic内部服务器之间进行内存复制的方案,这时候,就要开启Apusic应用服务器的集群服务。Apusic集群采用两种Session复制策略:多点复制,配对复制,用户可以根据自己的需要选择不同的复制策略。默认情况下为配对复制。
多点复制
多点复制即一个节点上的Session会即时复制到集群中其他节点。也就是说一个节点的Session在集群中同时存在多份备份。如下图:

当集群中某个节点收到来自客户端的请求(1),服务器生成Session(2),在请求处理完后,Apusic服务器会将session复制到集群中其他节点(3)。
在使用多点复制,当并发量很大的情况下,容易造成网络风暴,大大降低系统性能。
配对复制
所谓的配对复制,即一个节点的Session会即时复制到与其配对的服务器上。也就是说对于任一个节点的Session,在集群中只存在一份备份。当客户使用第三方的负载均衡器,并且负载均衡器提供Session stick功能时,使用配对复制能够提高服务器性能,减少网络风暴,但如果第三方的负载均衡器不提供Session stick功能时,使用配对复制并不会比多点复制性能好。如下图:

图中,Server1与Server4互为备份,Server2与Server3互为备份。当Server1收到来自客户端的请求(1),Server1生成Session(2),当请求处理完成后,将Session复制到Server4(3)。当Server3收到客户端请求(4),Server3生成Session(5),当请求处理完成后,将Session复制到Server2(6)。此时Server4中备份了Server1中的Session,Sever2中备份了Server3中的Session。
节点配对
Apusic提供两种方式设置节点配对:默认设置,手动设置。在默认设置的情况下,新加入节点寻找备份节点的策略为:首先找到第一个非本机的节点作为自己的备份节点,如果找不到,则会以本机的前一个节点作为自己的备份节点。如下图:

假设Server1,Server2,Server3,Server4依次加入集群,则Server1,Server2互为备份,Server3会以Server2为自己的备份,Server4以Server3为自己的备份。
当多个节点分布在不同的机器上时,如下图:

假设Server1,Server2,Server3,Server4,Server5,Server6依次加入集群,其中,Server1,Server2,Server5在同一台机器上,Server3,Server4,Server6在另一台机器上。当Server1加入时,此时没有任何配对节点,Server2加入,Server1与Server2互为配对。当Server3加入,Server3选择Server1为自己备份节点,此时Server1,Server2同时选择非本机的Server3为自己的备份节点。Server4加入,Server4选择Server1为自己的备份节点。Server5加入,Server5选择Server3为自己的备份节点,Server6加入,Server6选择Server1为自己的备份节点。
在默认设置的情况下有可能出现一台服务器成为多台服务器备份的情况,Apusic提供手动设置集群配对(如何手动设置节点配对,请参考配置Apusic应用服务器)。假设用户有四台服务器Server1,Server2,Server3,Server4,设置的配对为Server1与Server2互为备份,Server3与Server4互为备份。当节点依次加入集群时,Server1加入,没有备份,Server2加入,由设置的配对关系知Server1与Server2互为备份,当Server3加入,由于Server4没有加入,遵循默认节点加入寻找规则,找到Server1作为自己的备份,当Server4加入,Server4根据设置找到Server3作为自己备份,Server3这时发现自己的配对节点加入集群,重新找到Server4作为自己的备份。
节点状态同步
作为备份节点的服务器,必需要同步主服务器的状态(包括Session,Jndi等),这就涉及到节点状态同步。Apusic服务器提供节点状态的即时同步,即当主服务器选择了某个节点作为自己的备份服务器,这时主服务器会要求备份服务器节点同步主服务器节点的状态。
第二种方式,使用session分布式存储的:
Session 分布式存储主要是为了满足构建高水平扩展性及高可用性Web应用的需要。
Session分布式存储将Http Session集中存储在Key-Value DB中,由于Key-Value DB 提供了较高的读写性能及并发保护,给应用服务器水平扩展提供了有力支持。
Session分布式存储拓扑如下图所示:
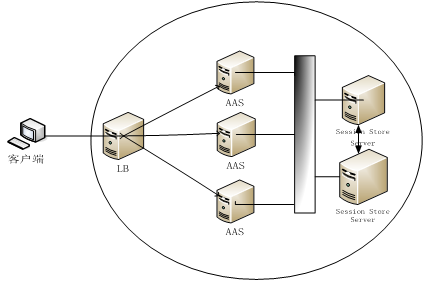
在集群中,应用运行在多个应用服务器中,若需提供失效转移的高可用性能力,Session数据在应用服务器中需要进行共享。
Session迁移的方式会造成网络风暴和服务器有效处理能力的下降,而在分布式存储中,Session 全部存储在Session Store Server中,节点间不再需要同步任何数据,当访问人数增加时,只需简单的添加应用服务器,提高系统的处理能力,实现了高可扩展性,且如果某个节点宕机后,其他节点将取代它,从Server中取得Session数据,继续为客户服务,实现高可靠性。
所以,分布式存储较适合于集群节点较多,且要求失效转移的高可用性、系统高扩展性的应用场合。
具体配置信息请参考第 60.2 节 “配置Apusic应用服务器”
Web集群的失效转移主要着眼于当处理请求的主服务器离开,当前用户的Session是否能够正确转移到其他的服务器上进行处理。在多点复制的情况下,主服务器离开,请求随机转发到其他服务器上,由于其他服务器存在当前的Session,这时可以继续处理用户的请求。在配对复制的情况下可能存在两种情况:
主服务器离开,请求被转发到备份服务器。这种情况和多点复制一样,备份服务器可以继续处理用户的请求。
主服务器离开,请求被转发到非备份服务器,这种情况下,非备份服务器会从备份服务器那将Session复制过来,继续处理请求。 那么当前服务器如何能够找到备份服务器呢?Apusic使用客户端Cookie机制,存储主服务器及备份服务器名称。当主服务器离开,请求发送到非备份服务器,非备份服务器通过Cookie里面的值知道备份服务器。如下图:


对不同的服务器厂商,对Session的复制粒度各有不同,典型的有三种:
复制全部Session 每次备份所有的Session,这种方案最简单。
复制新建及被修改的Session 当一个Session被创建或者被修改,服务器会将该Session复制到备份服务器。这种方案相比第一种方案能够大幅度提高性能。但是如何界定一个Session被修改,通常认为调用Session.setAttribute(), Session.removeAttribute()时,我们认为Session被修改。另外,对于被访问过但未修改的Session,Apusic会更新其备份服务器上Session的访问时间。
复制发生变化的属性 在Session发生变化时,不是备份整个Session,只对单个属性备份,这种方案能够取得更好的性能和更好的网络消耗。但是这时必须确保属性是可序列化的。同时也存在交叉引用的情况。
Apusic在Session的复制上,采用了第二种复制粒度。即对新建的和被修改Session,Apusic服务器才复制到备份服务器。另外备份Session发生的时机为完成每次请求后,Apusic服务器自动将修改的Session备份到备份服务器。 在备份Session过程中, 如果发现Session中的某个属性不可序列化,则默认丢弃,同时后台会有警告提示信息。当某个实现序列化的属性中存在非序列化的对象时,会在序列化过程中出错。
对于只需要负载均衡集群的用户,有三种方案:
前端,采用硬件负载均衡器;后端,部署多台Apusic应用服务器。
前端,部署Apusic LoadBalancer;后端,部署多台Apusic应用服务器。
前端,采用第三方软件负载均衡器或者Apusic Http Server;后端,部署多台Apusic应用服务器。
对于同时需要负载均衡和Session高可用的用户,则需要在多台Apusic应用服务器之间共享Session数据。当一台服务器失效后,可以把用户请求重定向到另外一台服务器进行服务,不会导致数据的丢失。服务器之间共享Session数据有2种方式:
启用Apusic应用服务器的集群服务和Session迁移功能。
使用分布式存储对Session进行存储。
这两种方式如何配置,请参考第 60.2 节 “配置Apusic应用服务器”。
以下着重讲述当前比较流行的Apache Server作负载均衡器,在Windows环境下如何配置Apusic集群。
1. 到Apache网站http://httpd.apache.org/下载Apache Server,目前版本为2.26.
2. 安装Apache Server,假设安装目录为:C:\Program Files\Apache Software Foundation\Apache2.2。到conf目录下打开文件httpd.conf,确保选项:
LoadModule proxy_module modules/mod_proxy.so LoadModule proxy_ajp_module modules/mod_proxy_ajp.so LoadModule proxy_balancer_module modules/mod_proxy_balancer.so LoadModule proxy_connect_module modules/mod_proxy_connect.so LoadModule proxy_http_module modules/mod_proxy_http.so
处于开启状态。同时在文件末尾加入如下配置:
<VirtualHost *:80> ProxyRequests off ProxyPass / balancer://test/ <Proxy balancer://test> BalancerMember http://localhost:6888 loadfactor=1 BalancerMember http://localhost:5888 loadfactor=1 BalancerMember http://localhost:4888 loadfactor=1 BalancerMember http://localhost:3888 loadfactor=1 </Proxy> </VirtualHost>
其中80端口是用户安装时配置的http协议监听端口,确认是否为80端口,可以查看Listen选项。BalancerMember为后置机节点,后面的值为后置机的地址和端口。Loadfactor为负载权重。当用户想使用会话粘滞(Session-Stick),可以在ProxyPass / balancer://test/ 后面加入stickysession=JSESSIONID,当用户想使用失效转移时要在后面加入nofailover=off,同时在每个BalancerMember最后面加入route=serverName。最终的配置形式如下:
<VirtualHost *:80> ProxyRequests off ProxyPass / balancer://test/ stickysession=JSESSIONID nofailover=off <Proxy balancer://test> BalancerMember http://localhost:6888 loadfactor=1 route=server3 BalancerMember http://localhost:5888 loadfactor=1 route=server2 BalancerMember http://localhost:4888 loadfactor=1 route=server1 BalancerMember http://localhost:3888 loadfactor=1 route=server0 </Proxy> </VirtualHost>
3. 配置Apusic应用服务器,如何配置apusic集群服务,请参考配置Web集群。
当用户想使用Session Stick时,只需要在apusic.conf文件中的SessionService中增加如下属性 :
<ATTRIBUTE NAME="SessionStick" VALUE="true"/>
4. 所有配置完成后,启动Apache Server和Apusic应用服务器.
注意:同时启动几台Apusic节点可能造成节点握手不成功,导致后加入节点不能正确加入集群,建议启动节点要依次加入。
5. 当使用Session配对复制时,用户可以通过Apusic AdminConsole设置节点之间配对关系。
Apusic应用服务器已经提供了文件存储,BerkelyDB存储及数据库存储Session的方式,这都极大地满足了Session钝化及备份的需求,然而,为什么还需要Session分布式存储呢?
Session分布式存储主要是为了满足构建高水平扩展性及高可用性Web应用的需要。若构建高水平扩展性、高可用性的Web应用,一般而言对Http Session有两种处理方案:
1、基于数据库的Session共享,实现分布式应用间Session共享。此种方案把Session信息存储到数据库表,这样实现不同应用服务器间Session信息的共享。
2、Session迁移。Session迁移即一个节点上的Session会即时复制到集群中其他节点。
以上两种方案都有其固有的缺点:前者的缺点是由于数据库服务器相对于应用服务器更难扩展且资源更为宝贵,在高并发的Web应用中,最大的性能瓶颈通常在于数据库服务器。
因此如果将Session存储到数据库表,频繁的增加、删除、查询操作很容易造成数据库表争用及加锁,最终影响业务。后者的缺点为:
当并发量很大的情况下,容易大量Session数据传输,造成网络风暴,同时服务器也需要不断对数据进行处理,减弱了服务器服务客户的有效处理能力,大大降低系统性能。
Session分布式存储较好的解决了以上问题,Http Session集中存储在Key-Value DB中,由于Key-Value DB 提供了较高的读写性能及并发保护,给应用服务器水平扩展提供了有力支持。
Session分布式存储拓扑如下图所示:
Session分布式存储主要用于构建满足可水平扩展及高可用Web应用集群。Web应用集群各个节点都把Http Session集中存储在一个或多个内存数据库中,避免各个节点相互同步HttpSession信息而造成的网络风暴,而各个节点也不需要对同步过来的HttpSession信息进行处理,提升了节点的服务有效处理能力。内存数据库以key-value的形式保存HttpSession信息,有很高的读写性能。由于集群各个节点HttpSession信息都使用相同的存储,如果需要在集群增加一个节点,只需要在新节点部署应用,然后把HttpSession信息存储到相同的存储即可,这就完成了给应用集群水平扩展,对其他节点毫无影响。
配置Apusic应用服务器,如何配置apusic集群服务,请参考第 30.3 节 “配置Session存储”。
Apusic应用服务器支持TokyoTyrant/TokyoCabinet 及Memcached-like 存储服务器。
Apusic应用服务器推荐使用TokyoTyrant,但其现阶段只支持Linux系统;Windows下可以考虑Membase,需将apusic.conf配置文件中TokyoTyrant设置为False。
Tokyo tyrant安装:
请先安装tokyo cabinet,再安装tokyo tyrant.后者依赖前者
1. 编译安装tokyo cabinet数据库
wget http://fallabs.com/tokyocabinet/tokyocabinet-1.4.47.tar.gz tar zxvf tokyocabinet-1.4. 47.tar.gz cd tokyocabinet-1.4. 47/ ./configure make make install
2. 编译安装tokyotyrant
wget http://tokyocabinet.sourceforge.net/tyrantpkg/tokyotyrant-1.1.29.tar.gz tar zxvf tokyotyrant-1.1.29.tar.gz cd tokyotyrant-1.1.29/ ./configure make make install
3. Tokyo tyrant 启动
启动tokyotyrant的主进程(ttserver)
a. 单机模式
ulimit -SHn 51200 ttserver -host 127.0.0.1 -port 11211 -thnum 8 -dmn -pid /ttserver/ttserver.pid -log /ttserver/ttserver.log -le -ulog /ttserver/ -ulim 128m -sid 1 -rts /ttserver/ttserver.rts /ttserver/database.tch
b. 双机互为主辅模式(相互备份)
服务器192.168.1.91:
ulimit -SHn 51200
ttserver -host 192.168.1.91 -port 11211 -thnum 8 -dmn -pid /ttserver/ttserver.pid -log
/ttserver/ttserver.log -le -ulog /ttserver/ -ulim 128m -sid 91 -mhost 192.168.1.92 -mport 11211
-rts /ttserver/ttserver.rts /ttserver/database.tch
服务器192.168.1.92:
ulimit -SHn 51200
ttserver -host 192.168.1.92 -port 11211 -thnum 8 -dmn -pid /ttserver/ttserver.pid -log
/ttserver/ttserver.log -le -ulog /ttserver/ -ulim 128m -sid 92 -mhost 192.168.1.91 -mport 11211
-rts /ttserver/ttserver.rts /ttserver/database.tch
c. 参数说明
ttserver -host -port -thnum -tout [-dmn] -pid -log [-ld|-le] -ulog -ulim [-uas] -sid -mhost -mport -rts [dbname]
-host name : 指定需要绑定的服务器域名或IP地址。默认绑定这台服务器上的所有IP地址。
-port num : 指定需要绑定的端口号。默认端口号为1978
-thnum num : 指定线程数。默认为8个线程。
-tout num : 指定每个会话的超时时间(单位为秒)。默认永不超时。
-dmn : 以守护进程方式运行。
-pid path : 输出进程ID到指定文件(这里指定文件名)。
-log path : 输出日志信息到指定文件(这里指定文件名)。
-ld : 在日志文件中还记录DEBUG调试信息。
-le : 在日志文件中仅记录错误信息。
-ulog path : 指定同步日志文件存放路径(这里指定目录名)。
-ulim num : 指定每个同步日志文件的大小(例如128m)。
-uas : 使用异步IO记录更新日志(使用此项会减少磁盘IO消耗,但是数据会先放在内存中,
不会立即写入磁盘,如果重启服务器或ttserver进程被kill掉,将导致部分数据丢失。一般情况下不建议使用)。
-sid num : 指定服务器ID号(当使用主辅模式时,每台ttserver需要不同的ID号)
-mhost name : 指定主辅同步模式下,主服务器的域名或IP地址。
-mport num : 指定主辅同步模式下,主服务器的端口号。
-rts path : 指定用来存放同步时间戳的文件名。
dbname:数据库名字。Tokyo Tyrant使用数据库名字后缀指定数据库类型。
下面我们再来看下数据库类型的详细配置:
如果数据库名为"*",表示内存hash数据库。
如果数据库名为"+"表示内存tree数据库。
如果数据库名为".tch",则数据库为hash数据库。
如果数据库名的后缀为".tcb",数据库将为B+ tree数据库。
如果数据库名的后缀为".tcf"。则数据库将为fixed-length数据库。
如果数据库名的后缀为".tct",则数据将为一个table数据库(有表的概念)。
停止tokyotyrant(ttserver)
ps -ef | grep ttserver,找到ttserver的进程号并kill,例如:kill -TERM 2159
1、安装中可能遇到问题
在Ubuntu ,OpenSuse中可能因为依赖而导致不成功,具体问题如下:
1)、缺少bzlib.h文件
解决方法:下载及安装这两个安装包
i、bzip2-1.0.4.tar.gz
ii、zlib-1.2.3.tar.gz
2)tc make file时候,当碰到依赖libbz2.a或者libz.a这两个库的时候会出现编译错误。
//***************************************************************************// /usr/bin/ld: /usr/local/lib/libbz2.a(bzlib.o): relocation R_X86_64_32S against `a local symbol' can not be used when making a shared object; recompile with -fPIC /usr/local/lib/libbz2.a: could not read symbols: Bad value collect2: ld 返回 1 make: *** [libtokyocabinet.so.8.22.0] 错误 1 //***************************************************************************// /usr/bin/ld: /usr/local/lib/libz.a(crc32.o): relocation R_X86_64_32 against `a local symbol' can not be used when making a shared object; recompile with -fPIC /usr/local/lib/libz.a: could not read symbols: Bad value make: *** [libtokyocabinet.so.8.22.0] 错误 1 //***************************************************************************//
解决方法:
1、删除文件libbz2.a,libz.a
如果发现 libbz2.a: could not read symbols: Bad value,就应该把/usr/local/lib中的libbz2.a删掉。进入解压缩的zlib-1.2.3目录,用make clean命令清理一下。
同样,/usr/local/lib/libz.a: could not read symbols,操作同上,删掉libz.a,把bzip2-1.0.4目录的编译文件清理一下。如果找不到这两个文件的位置,可以在终端敲上:find -name libbz2.a。
2、修改zlib-1.2.3的Makefile文件
把gcc的编译参数加上 -fPIC,原文:CFLAGS=-O3 -DUSE_MMAP修改为:CFLAGS=-O3 -DUSE_MMAP -fPIC。如果还是过不去,劝你硬来CC=gcc 直接后面跟上-fPIC让他们全部独立编译。
重申:如果你之前编译过了,一定要用make clean清掉,否则还是徒劳。最后make 还有 make install。
3、修改bzip2-1.0.4的Makefile文件
CC=gcc -fPIC AR=ar RANLIB=ranlib LDFLAGS= BIGFILES=-D_FILE_OFFSET_BITS=64 CFLAGS=-fPIC -Wall -Winline -O2 -g $(BIGFILES)
4、重新安装Tokyo cabinet
JNDI作为JEE的基础技术,是J2EE中提供使用资源的间接层。JNDI集群往往是其它上层集群技术的必要条件.
我们知道,JNDI命名是以层次结构来组织的,在示意图中,往往用树来表达,所以称为JNDI树。
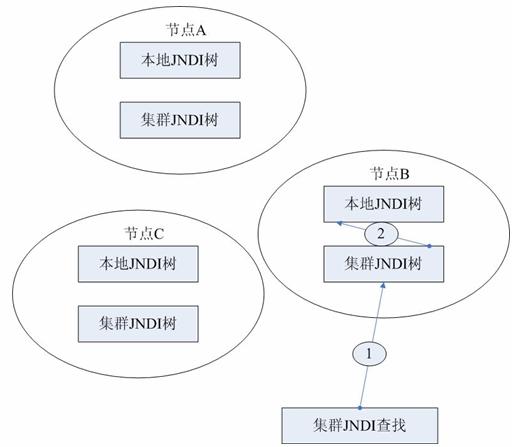
那么,JNDI集群又是怎么回事呢?
JNDI集群是Apusic服务器提供的一个服务,一旦启用这个服务,集群的各节点(指Apusic服务器)都拥有一个集群JNDI树,它有别于本地JNDI树,事实上,在JNDI集群节点中,这两棵树是同时存在的,那么它们的区别和联系又在哪里?
各节点的本地JNDI树是彼此独立的,遵循J2EE JNDI标准语义、习惯用法,而它们的集群JNDI树之间会遵循如下规则协作。
在集群中,某个服务器节点集群JNDI树上的操作都会传播到其它节点的集群JNDI树上。 譬如在某节点bind(“a”,”a”),那么其它节点的集群JNDI树上也会存在名值对(“a”,”a”)。当然,这里可能出现名字冲突的问题,譬如,A节点首先bind(“a”,”a”),并且传播到其它节点,随后,B节点bind(“a”,”aa”),那么会出现什么情况呢?对于这种情况,我们只会将B节点的a与aa绑定,而集群内的其它节点保持不变。如果你需要集群范围所有的集群JNDI树上的名值对(“a”,”a”)全部更新为(“a”,”aa”),你需要使用rebind方法。
当你持有一个集群JNDI上下文,并且使用它lookup的时候,它首先在集群JNDI树上搜索,搜不到,还会到本地JNDI树上搜索(如上图所示)。
什么是JNDI负载均衡(LoadBalance)和JNDI失效恢复(Fail-Over)?它试图解决的是什么问题?
场景:某公司C部署了一台Apusic服务器S1,并且通过本地JNDI发布了服务(n,s),系统客户端遵循常规JNDI用法,指定S1为provider。显然,服务器都存在失效的可能,而且,随着业务的扩展,服务量的增加,一台服务器,已经不能满足需求,服务质量(系统响应时间和系统可用性)急待提高。公司又增加两台服务器S2、S3,S2、S3同样通过本地JNDI发布了服务(n,s),此时,系统客户端怎样和S1、S2、S3交互成为问题的关键所在。理想的情况是,系统客户端的服务请求被合理地分配到S1、S2、S3上,一旦,其中一台或多台服务器失效,服务请求会透明地、合理地被分配到剩下的有效的服务器上。
上述场景中的服务请求被合理地分配到多台服务器的行为就称作JNDI负载均衡,而一台或多台服务器失效后,服务请求通明、合理地被分配到剩下地有效的服务器上的行为就称作JNDI失效恢复.
启用Apusic JNDI集群服务,你需要在%DOMAIN_HOME%\config\apusic.conf中配置ClusterNameService服务,片断如下:
<SERVICE CLASS="com.apusic.naming.cluster.ClusterNameService"/>
当然,由于ClusterService服务是ClusterNameService服务的基础,所以,你需要保证在%DOMAIN_HOME%\config\apusic.conf中已经配置ClusterService服务(如何配置ClusterService服务请参考配置Web集群).
上面提及,无论使用本地JNDI还是集群JNDI,首先我们必须获取相应的JNDI上下文(一般都是初始上下文)。本地JNDI的使用遵循JNDI标准,示例代码片断:
Hashtable env = new Hashtable(); //You can specify Apusic-specific properties here. env.put(Context.INITIAL_CONTEXT_FACTORY,”com.apusic.naming.jndi.CNContextFactory); env.put(Context.PROVIDER_URL,”iiop://192.168.6.55”); //something omitted. … Context ctx = new InitialContext(env);
如果你试图获取集群JNDI初始上下文而不是本地JNDI初始上下文,那么你需要在客户端设定环境变量:
apusic.naming.clustering=true
那么在哪里设定上述环境变量呢?你可以使用命令行参数;你也可以通过编码在JNDI初始上下文属性中指定;甚至,你可以将之写入JNDI实现jar包的jndi属性配置文件中(不推荐)。
下面是第二种方式的示例代码片断:
Hashtable env = new Hashtable(); //You can specify Apusic-specific properties here. env.put(“apusic.naming.clustering”,”true”); env.put(Context.INITIAL_CONTEXT_FACTORY,”com.apusic.naming.jndi.CNContextFactory); env.put(Context.PROVIDER_URL,”iiop://192.168.6.55”); //something omitted. … Context ctx = new InitialContext(env);
为了启用Apusic JNDI负载均衡和失效恢复能力,你只需要在客户端设定环境变量java.naming.provider.url=<provider-list>.你可以通过多种方式来设定。推荐方式是在JNDI初始上下文的PROVIDER_URL属性中指定<provider-list>,<provider-list>格式示例如下:
iiop://S1:6888,S2:6888,S3:6888
显然,硬编码总是缺乏灵活性,所以,Apusic还提供了JNDI provider的发现(discovery)功能,你不需要通过PROVIDER_URL属性指定任何provider,你只需要在客户端设定如下环境变量:
apusic.naming.discovery=true apusic.naming.discovery.address=230.0.0.2 apusic.naming.discovery.port=1500 apusic.naming.discovery.timeout=5000 apusic.naming.discovery.cluster_name= ApusicCluster
其中,apusic.naming.discovery=true是必须的,剩下的四个环境变量,除apusic.naming.discovery.cluster_name,其它三个如果省略,那么如上默认值会被采用。当然,别忘了在%DOMAIN_HOME%\config\apusic.conf中配置DiscoveryService服务,片断如下:
<SERVICE CLASS="com.apusic.net.DiscoveryService"> <ATTRIBUTE NAME="GroupAddress" VALUE="230.0.0.2"/> <ATTRIBUTE NAME="GroupPort" VALUE="1500"/> </SERVICE>
Apusic应用服务器支持EJB3.0,同时兼容EJB2.x、EJB1.x。EJB集群是解决大规模、具有厚重而复杂的商业逻辑、高性能、高可用、高水平可扩展的JavaEE系统的良好方案。Apusic为SessionBean、EntityBean集群提供简洁有效、独具特色的支持。
Apusic EJB集群主要面向两个问题:负载均衡和高可用性。值得注意的是,EJB集群一般都是针对EJB远程调用而言,而非本地调用(包括集群节点内部使用远程接口,因为对于这种情况,Apusic会自动优化成本地调用)。以下叙述,对于Home接口、Bean接口,如果如果没特殊说明,均指远程的。
首先,以EJB2.x编程模型为例,我们看看SessionBean、EntityBean的典型应用模式。
一个典型的SessionBean应用代码片断:
… Context ctx = …; CounterHome counterH = (CounterHome) PortableRemoteObject.narrow(ctx.lookup(“ejb/Counter”),CounterHome.class); Object o = counterH.create(/*may be ,some initial states for stateful session bean.*/); Counter counter = PortableRemoteObject.narrow(o,Counter.class); counter.add(1); counter.minus(100); …
一个典型的EntityBean应用代码片断:
… Context ctx = …; AccountHome accountH = (AccountHome) PortableRemoteObject.narrow(ctx.lookup(“ejb/Account”),AccountHome.class); Object o = accountH. findByPrimaryKey(new AccountPK(“ISN”)); Account account = PortableRemoteObject.narrow(o,Accout.class); account.deposit(1); account.withdraw(100); …
从上面代码片断我们可以看出,典型的EJB应用,首先获取Home接口,然后通过Home接口获取Bean接口,最后通过Bean接口调用业务方法完成商业计算(如下图):
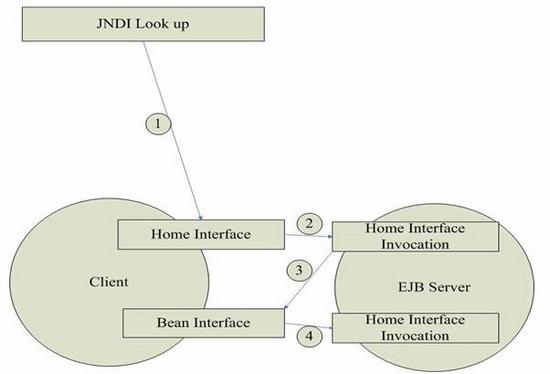
那么,EJB负载均衡、EJB高可用性是怎么回事?
沿袭负载均衡一贯的语义,EJB负载均衡指EJB调用通过特定算法分配到多台应用服务器的行为。这里的EJB调用指对EJB Bean接口的调用。然而,Apusic EJB集群还支持Home接口的负载均衡。
目前,Apusic EJB集群支持的负载均衡算法有:
RANDOM
随机选择集群有效节点中的一个.
ROUND_ROBIN
循环地、依次地选择集群有效节点中的一个.
WEIGHTED
根据集群节点预先设定的负载权重进行选择。权重通过服务ClusterService的LoadWeight属性设置,范围是[1,100]。一般来说,WEIGHTED用于非对称集群,譬如,集群中有两台服务器S1、S2,S1计算能力强于S2,那么可以根据计算能力的比例为S1、S2设置恰当的权重值,从而,使得计算能力强的服务器接收、处理更多的请求。
STICKY
在获取Bean接口、通过Bean接口调用业务方法的时候,随机选择一个节点,此后,获取Bean接口、调用Bean接口的业务方法的调用全部发送到这个节点,除非这个节点失效。
EJB高可用性指在某集群节点失效的时候,对它的EJB Home接口的调用或者Bean接口的调用会透明地转移到其它有效节点。
事实上,EJB集群的配置是相当简单的,你只需要在apusic-application.xml的Bean配置中添加如下格式的片断:
<cluster-config> <clustered>true</clustered> <home-load-balance-policy>ROUND_ROBIN</home-load-balance-policy> <object-load-balance-policy>ROUND_ROBIN</object-load-balance-policy> </cluster-config>
其中<home-load-balance-policy>配置Home接口的负载均衡算法。<object-load-balance-policy>配置Bean接口的负载均衡算法。当然,以上两个配置是可选的,你可以简单添加片断:
<cluster-config> <clustered>true</clustered> </cluster-config>
此时,Apusic会根据Bean的类型决定Home接口和Bean接口的负载均衡算法。决策为所有类型的Bean,Home接口采用ROUND_ROBIN算法;SLSB和只读EntityBean的Bean接口采用ROUND_ROBIN算法;SFSB和非只读EntityBean的Bean接口采用STICKY算法。以下是集群SLSB的apusic-application.xml的片断:
<apusic-application>
<module uri="">
<ejb>
<session ejb-name="GreetingBean">
<jndi-name>ejb/GreetingHome</jndi-name>
<local-jndi-name>ejb/GreetingLocalHome</local-jndi-name>
<security-mechanisms/>
<cluster-config>
<clustered>true</clustered>
<home-load-balance-policy>ROUND_ROBIN</home-load-balance-policy>
<object-load-balance-policy>ROUND_ROBIN</object-load-balance-policy>
</cluster-config>
</session>
</ejb>
</module>
</apusic-application>同时,别忘了,在%DOMAIN_HOME%\config\apusic.conf中配置ClusterService服务。
关于Home接口和Bean接口负载均衡算法的选择
理论上,任何类型Bean的Home接口和Bean接口都可以采用RANDOM、ROUND_ROBIN、WEIGHTED、STICKY算法。不过,显然,集群节点计算能力不对称、各种Bean的特性、各种Bean集群的特定实现方式等等因素都会影响甚至决定均衡算法的选择。
如果集群节点计算能力不对称,优先考虑WEIGHTED算法。
由于Apusic SFSB、非只读EntityBean集群的特定实现方式,所以它们的Bean接口最好采用STICKY算法。
关于集群节点内部的EJB调用
上面,我们提到,一般来说,EJB集群针对远程调用而言。同时,存在这样的事实:对于节点内部的EJB远程调用,Apusic会自动将之优化成本地调用。所以,包括Web-EJB、EJB-EJB等方式在内的集群节点内部的EJB调用(无论使用远程接口还是本地接口),最终都变成本地调用,同时负载均衡和高可用性特性消失。
关于EntityBean一定程度的状态同步
Apusic EJB 容器支持EJB2.1规范提及的A、B、C三种commit-time option。很显然,基本上,EntityBean集群场景是不符合option A的假定,更重要的是,Apusic EJB集群依赖数据库同步,所以,一般来说,concurrency-strategy设定为Exclusive并且force-refresh设定为False,这样的方案绝对不应采用,而Concurrency-strategy采用Parallel策略是推荐方案。
关于安全角色的传播
要使节点间EJB调用的安全角色能够传播,必须使用一致的认证密钥,即%DOMAIN_HOME%\config\authkey.dat必须一致。可以先启动一个Apusic服务器,生成config/authkey.dat文件,然后将此文件复制到其他服务器。
JMS是JavaEE相当重要的一部分,它为开发异步、可靠、高性能、灵活的系统提供支持。目前广泛应用于EAI、EDI等领域。Apusic JMS集群主要包括消息路由和集群队列功能。
消息路由一般用来解决发送消息的客户端和消息目的地不能直接连通的情况下,依赖特定算法,选择JMS网络中的一个或多个中间消息路由器(Router)组成的能够到达消息目的地的最优通路并负责转发消息。
在一个由多台提供消息服务的 Apusic 应用服务器组成的网络上,每个提供消息服务的 Apusic 应用服务器可被视为一个网络中的节点,消息路由意味着节点之间的路径。只要用户连接到网络中任何一个节点,即可向网络中的其他任意节点发送消息,由消息服务根据消息路由提供消息在网络中的最佳传输机制。
如下图所示:

A、B、C、D、E五个节点上都是提供消息服务的Apusic应用服务器,五个节点连通成一个网络,连接到A节点的客户端可以发消息到五个节点中的任意一个节点,Apusic应用服务器会自动寻找一条最佳路径传递消息到目标节点。如从A发消息到D,有两条连通路径:A->B->C->D和A->E->D,其中A->E->D经过的节点最少,该路径为最佳路径,Apusic应用服务器将根据此路径对消息进行传递。

在一个Apusic应用服务器JMS网络中,如上图所示,每个节点都是一个消息路由器(Router),每个消息路由器有一个路由器名,以区别于其他的路由器。路由器名可以和主机名相同,也可以不同。
每两个节点之间的直接路径被称为路由连接器(RoutingConnector),网络中每两个节点间的直接路径必须事先进行申明性的定义。每个路由连接器的申明都是双向的,如在A节点上申明到B的路由连接器,则说明从A节点到B节点之间是双向连通的,从A可以到达B,从B也同样能够到达A。
假设上图中的五个节点A、B、C、D、E是某个实际网络中五个提供消息服务的Apusic应用服务器,实际网络中的主机名分别是computerA、computerB、computerC、computerD、computerE,在由这五个节点组成的Apusic应用服务器网络中,服务器配置的路由器名分别是routerA、routerB、routerC、routerD、routerE,要使这五个节点结形成类似于上图的Apusic应用服务器 网络,即每个节点都有一条与下一个节点双向连通的路径,最后一个节点有一条与最开始的节点双向连通的路径,形成一个闭合的环,消息客户连接到环中的任意节点,都可向其他节点发送消息。则可以选择在每个节点上都申明一个到下一个节点的连接器,由于连接器是双向连通的,所以在下一个节点不需要申明一个到上一个节点的连接器。同时在每个节点上的远程路由需要申明跟它直接相连的其它节点的路由名。如:A节点上的远程路由需要申明B、E两个节点,表示由A节点可以直接连接到B、E两个节点上,并且不需要申明其它节点,这样A就能够向所有的节点发送消息了。同时需要申明由A到B的连接器,表示A节点跟B节点有一条双向连通的路径;节点B的远程路由则需要申明A、C两个节点,同时需要申明由B到C的连接器,如此类推。
JMS是JavaEE规范中提出的消息中间件服务(Java Message Service™)规范,提供应用程序间异步或同步的消息传递和管理服务,Apusic 应用服务器中包含了高效、可靠的消息服务。Apusic应用服务器中的消息服务接口完全遵循JMS API规范。提高了企业应用中各组件的可移植性、松耦合特性,同时更加高效可靠;为分布式企业应用异步交换关键业务数据和事件提供了可靠而灵活的服务。
Apusic消息服务提供对消息队列(Queue)和消息主题(Topic)的管理,消息的发送由消息服务负责完成,原理如下:

ComputerA,B,C为提供消息服务的Apusic应用服务器,每一个Apusic应用服务器称为一个Router,他们之间的连接被称为Connector,客户端进行消息发送时直接与Computer A 连接,客户端要把消息传送到Computer B 的队列时,只需指明接收消息的主机名和队列名,然后发送消息即可,Computer A 中的消息服务将会查找配置文件中的设置,如从A 到B间有无通路连通,假如它们之间有通路连接,消息服务就会寻找这些通路中最短的路径发送消息到指定服务器(Computer B) 的指定队列,假如A 到B 间无有效连接,消息将被保存在某一连通的服务器上,待有有效通路之后再发送消息。
Apusic应用服务器提供了两个主要的消息服务方面的特性:
全局事务
Apusic应用服务器提供了一个作为事务性资源管理器的JMS提供者(Provider),允许从JSP,Servlet,EJB等应用组件中对消息服务进行事务性的访问。对消息的发送和接收可以和对其他资源的操作一起参与到一个JTA事务中。
Message-drivenBeanJ2EE™1.3规范中提供的EnterpriseBean类型,Message-drivenBean,使多层分布式企业应用可以异步地使用消息。
多个提供消息服务的应用服务器可以组成一个虚拟的JMS网络,每个提供消息服务的应用服务器可被视为一个JMS网络中的节点,而节点之间的连接则通过声明消息路由提供。只要用户连接到JMS网络中任何一个节点,即可向网络中的其他任意节点发送消息。
为提供消息服务的可靠性,和JMS网络中消息的暂时存储,Apusic应用服务器使用了一个可靠的消息存储机制。
配置消息存储目录
Apusic消息路由与存储配置的部分存在于域主目录下config子目录中,apusic.conf文件中的相关配置段。缺省的配置段如下:
...
<SERVICE
CLASS="com.apusic.jms.server.FileMessageStoreProvider"
>
<ATTRIBUTE NAME="StoreDirectory" VALUE="store/jms"/>
</SERVICE>
...此配置段指定了消息服务的存储目录,其中,名为StoreDirectory属性的值指定了消息存储目录的路径,可使用绝对路径如:c:\message_store\或/usr/message_store来指定,亦可使用相对于域主目录的相对路径如:store/my_message_store来指定,如指定目录不存在,应用服务器将创建指定的目录。
配置消息路由
对消息服务中路由的配置是通过Apusic应用服务器域主目录中子目录config下的apusic.conf 配置文件进行的。通过apusic.conf中的相关配置段可以对消息路由器和路由连接器进行管理和配置。
路由器的配置
消息路由器的配置通过在apusic.conf文件中配置消息服务的服务配置段进行,其缺省配置段如下:
<SERVICE CLASS="com.apusic.jms.server.JMSServer"> </SERVICE>
通过对申明此服务的XML元素增加名为RemoteRouters的ATTRIBUTE子元素,在其值中列出相应的路由器名即可。以消息路由图示-2中的A节点为例,A节点上需要申明B、E两个节点,表示由A节点可以直接连接到B、E两个节点上,并且可以作为消息路由路径中的一个中转节点,则可以进行如下配置:
<SERVICE
CLASS="com.apusic.jms.server.JMSServer">
<ATTRIBUTE NAME="RemoteRouters" VALUE="computerB,computerE"/>
</SERVICE>其它B、C、D、E节点上的相关配置段如此类推进行配置。路由器名字间使用逗号分隔,路由器名字可以是其他主机的主机名。
一般,路由器的名字默认是服务器的主机名,但是,也可以通过使用对申明此服务的XML元素增加名为RouterName的ATTRIBUTE子元素,在其值中指定自身的路由器名。 如上例中采用了主机名对路由连接器进行申明,如在五个节点上都申明了路由器名字,如A、B、C、D、E主机分别对应routerA、routerB、routerC、routerD、routerE,则上例的配置如下:
<SERVICE
CLASS="com.apusic.jms.server.JMSServer">
<ATTRIBUTE NAME="RouterName" VALUE="routerA"/>
<ATTRIBUTE NAME="RemoteRouters" VALUE="routerB,routerE"/>
</SERVICE>其它路由器的配置依次类推。
路由连接器的配置
每个JMS网络中的消息路由器都是通过路由连接器进行连接的,每个路由器可以拥有多个路由连接器连接到其它节点。对路由连接器的配置是通过在apusic.conf配置文件中增加路由连接器服务实现的。以消息路由图示-2中的A节点为例,需要申明到节点B的路由连接器,则可在apusic.conf文件中加入如下配置段:
<SERVICE
CLASS="com.apusic.jms.routing.RoutingConnector" NAME="Connector:Name=toB">
<ATTRIBUTE NAME="RemoteHost" VALUE="computerB"/>
<ATTRIBUTE NAME="RemotePort" VALUE="6888"/>
</SERVICE>其中computerB是B的主机名,toB是此路由连接器区别于其他路由连接器的自由定义名字,6888是默认的JMS服务端口,具体使用中,可将其更改为实际的路由连接器名、主机名与端口。
消息服务的管理是通过配置消息管理对象的属性完成的。消息管理对象包含了管理员生成的消息配置信息,之后由消息客户端使用。
消息服务中定义了两个管理对象:
连接工厂(ConnectionFactory)。消息客户通过此对象创建与消息服务的连接.
消息目的地(Destination)。消息客户用来指定发送消息的目的地或接收消息的来源地。
由于消息服务包含两种消息模型,即Point-to-Point(PTP)和Publish-and-Subscribe(Pub/Sub)模型,Apusic应用服务器对这两种消息模型提供了完整的支持,因此,对于连接工厂而言,提供了两种可配置的连接工厂类型,面向PTP消息模型的QueueConnectionFactory和面向Pub/Sub模型的TopicConnectionFactory;对于消息目的地而言,同样提供了两种可配置的消息接收类型站,面向PTP的队列(Queue)站和面向Pub/Sub的主题(Topic)站。
通过对存在于Apusic应用服务器域主目录下config子目录中,名为jms.xml的配置文件进行编辑,实现对Apusic应用服务器消息服务的管理。在此文件中,可以对连接工厂、消息目的地和消息服务安全策略进行配置。
jms.xml文件是一个xml文件,其文档类型定义(DTD)为jms-config_1_2.dtd。
1. 配置连接工厂
在jms.xml文件中,每一个连接工厂配置信息对应一个connection-factory标记申明的xml元素,每个connection-factory元素可包含使用以下三种标记所申明的子元素:
description,可选标记,对此连接工厂的描述 .
display-name,必须申明的标记,用于区别于其它连接工厂.
jndi-name,可选标记,通过JNDI,用于客户在服务器命名空间中查找此连接工厂.
实际应用中,当管理员为连接工厂分配JNDI名之后,消息客户即可使用JNDI在服务器的命名空间中对连接工厂进行查找并获得引用,之后通过连接工厂取得与消息服务的连接。
连接工厂的配置属性如下表:
| 属性 | 描述 | 值类型 | 缺省值 |
| pooled | 指定此连接工厂是否对其管理的连接使用连接池 | “True”或“False” | “False” |
| secure | 指定连接工厂所提供连接的通讯方式 | “True”或“False” | “False” |
| anonymous | 是否授权匿名用户访问此连接工厂 | “True”或“False” | “True” |
| client-id | 由于标识连接客户状态的标识符,通常被用于Pub/Sub模型中的持久订阅(Durable subscription) | 字符串,此属性是可选的 | 无 |
| default-delivery-mode | 使用由此连接工厂生成的连接发送消息时,缺省的发送方式 | “persistent”或“non-persistent” | “non-persistent” |
| default-priority | 使用由此连接工厂生成的连接发送消息时,缺省的优先级 | 数字(0~9) | 4 |
| default-time-to-live | 使用由此连接工厂生成的连接发送消息时,对于已发送的消息,消息系统保留此消息的缺省时间长度,单位为毫秒。 | 整型 | 0 |
| min-pool-size | 此连接工厂对应的连接池中,所保持的最少连接数 | 整型 | 5 |
| max-pool-size | 此连接工厂对应的连接池中,所保持的最大连接数 | 整型 | 30 |
| idle-timeout | 连接等待超时时间。当连接池中的某个连接等待被使用的实际时间超过此属性数值时,连接池自动关闭此连接 | 整型(单位秒) | 300 |
2. 配置消息目的地
对应于PTP和Pub/Sub消息模型,Apusic应用服务器中的消息服务提供了两种消息目的地,队列(Queue)和主题(Topic)。实际应用中,管理员为消息目的地分配JNDI名,消息客户即可使用JNDI在服务器的命名空间中对消息目的地进行查找并获得引用,在通过连接工厂取得与消息服务的连接之后,消息客户即可向消息目的地同步或异步地发送或接收消息。
在jms.xml文件中,每一个消息目的地配置信息对应一个queue标记或topic标记申明的xml元素。
配置消息队列(Queue)
在jms.xml文件中,每一个队列(Queue)配置信息对应一个queue标记申明的xml元素,每个申明的queue元素可包含三种标记所申明的子元素:
description,可选标记,对此队列的描述 ;
display-name,必须申明的标记,用于区别于其它队列;
jndi-name,可选标记,通过JNDI,用于客户在服务器命名空间中查找此队列。
队列的配置属性如下表:
| 属性 | 描述 | 值类型 | 缺省值 |
| cache-size | 队列缓冲中保留的消息个数 | 整型 | 20 |
| expiry-check-interval | 系统检测消息队列中消息是否过期的时间间隔,单位是秒 | 整型 | 60 |
配置消息主题(Topic)
在jms.xml文件中,每一个主题(Topic)配置信息对应一个topic标记申明的xml元素,每个申明的topic元素可包含三种标记所申明的子元素:
description,可选标记,对此主题的描述
display-name,必须申明的标记,用于区别于其它主题
jndi-name,可选标记,通过JNDI,用于客户在服务器命名空间中查找此主题
主题的配置属性如下表:
| 属性 | 描述 | 值类型 | 缺省值 |
| cache-size | 队列缓冲中保留的消息个数 | 整型 | 20 |
| expiry-check-interval | 系统检测消息队列中消息是否过期的时间间隔,单位是秒 | 整型 | 60 |
安全相关配置
JavaEE™体系中的JMS规范实际上并未包含有关安全方面的内容,因此,系统提供保证消息服务的安全和完整性的机制就极为重要。
Apusic应用服务器提供了对消息服务方面的安全管理,主要根据JavaEE™体系中的安全角色(SecurityRole)和消息客户的操作对消息服务进行保护。
消息服务中基于安全角色的授权方式是指,系统管理员可定义一组安全角色,每个被定义的安全角色对应于系统中的一组用户或组,然后,根据消息客户用户可对消息目的地(Destination)进行的操作(如对于队列,客户可执行发送、接收、浏览等操作)对前面定义的安全角色进行授权。
安全角色
在jms.xml文件中,每一个安全角色(Security Role)配置信息对应一个security-role标记申明的xml元素,每个申明的security-role元素可包含四种标记所申明的子元素:
description,可选标记,对此安全角色的描述 。
role-name,必须申明的标记,用于区别于其它安全角色申明。
principal或group,必须使用至少一个这两种标记申明的元素,可以是多个,用于将逻 辑的安全角色对应于系统中的用户或组。
消息目的地(Destination)访问许可
对于一个或者一组jms.xml中申明的消息目的地(Destination)和一个或者一组jms.xml中申明的安全角色,通过使用一个destination-permission标记申明的xml元素来设置这二者之间的对应关系, 每个申明的destination-permission元素可包含三种标记所申明的子元素:
description,可选标记,对此访问许可的描述 。
role-name,必须使用至少一个这种标记申明的元素,可以是多个,用于表示此访问许可 所包含的在security-role中申明的安全角色。
destination-method,必须使用至少一个这种标记申明的元素,可以是多个,用于表示 此访问许可所包含的客户对消息目的地(Destination)能进行的操作。
每个申明的destination-method元素可包含四种标记所申明的子元素:
description,可选标记,对此destination-method的描述 。
queue-name或topic-name,必须有至少一个这两种标记申明的元素,而且它的 值必须是对应的jms.xml中已申明的queue或topic元素,用于说明此访问许可包含的消息目的地(Destination)。
method-name,必须使用至少一个这种标记申明的元素,可以是多个,通过方法名, 指定对指定队列(queue)或主题(topic)所能进行的客户操作。对于指定的队列(queue),每个method-name元素的值可以是send、receive或browse中之一;对于指定的主题(topic),每个method-name元素的值可以是publish、subscribe、subscribe-durable或unsubscribe中之一。
范例
下面范例授权安全角色foo可以对队列bar 进行接收和浏览:
申明队列
... <queue> <queue-name>testQueue</queue-name> </queue> ...
申明安全角色foo,并对应到管理员用户
... <security-role> <role-name>foo</role-name> <principal>admin</principal> </security-role> ...
设置访问许可
...
<destination-permission>
<role-name>foo</role-name>
<destination-method>
<queue-name>testQueue</queue-name>
<method-name>receive</method-name>
<method-name>browse</method-name>
</destination-method>
</destination-permission>
...
基于JMS的系统同样存在负载均衡和可用性的问题。集群队列基于消息路由技术,它能够很好的解决这两个问题。
集群队列是指JMS网络中的任何一个节点上定义的消息队列都将被其他节点所共享,通过任何节点向一个集群队列发送消息都是等效的,对客户来说无法察觉是否正在使用集群,集群中网络拓扑结构发生变化对客户端也没有任何影响。
集群队列具有高可用性:JMS网络中单个节点失效或部分网络无法连通时并不影响集群队列的使用.
集群队列具有负载均衡特性:在发送消息时,根据各节点的负荷情况,负载会被合理分配,从而使节点处理能力和网络带宽被充分利用。
要使用集群队列,你只需要在jms.xml中,为某个队列添加clustered属性,示例片断:
<queue clustered="true"> <queue-name>clusteredQueue</queue-name> </queue>
典型的JMS应用中,无论发送、接收消息,都需要通过某种方式获取目的地(Destination,为Queue或者Topic),一般,我们通过JNDI来获取,示例代码片断如下:
Context ctx = …; Session ssn = …; Queue queue = (Queue)ctx.lookup(“TestQueue”); …
那么我们又怎样获取集群队列呢?其实,很简单,我们需要通过JMS Session接口的方法Queue createQueue(String queueName)来获取,以上面注册的clusteredQueue为例,代码片断如下:
Session ssn = …; //get session instance Queue queue = ssn.createQueue(“clusteredQueue”); …